
Comment les mathématiques aident-elles à détecter la fraude fiscale ? (Loi de Benford)

Introduction
Lutter contre la fraude fiscale, c’est un vrai défi : chaque année, des milliards d’euros échappent aux États à cause de comptes truqués, de fausses factures ou de chiffres arrangés. Mais les fraudeurs oublient souvent une chose… les mathématiques, elles, ne mentent jamais.
En effet, lorsqu’on observe des données réelles, les chiffres suivent des régularités surprenantes. C’est ce qu’on appelle la loi de Benford
Problématique : dans quelle mesure la loi de Benford et d’autres méthodes statistiques permettent-elles de repérer une fraude fiscale ?
I. Les nombres et leurs régularités cachées
1. Une intuition surprenante
Exemple rapide : sur les factures d’électricité, on trouve bien plus de montants commençant par 1 (120€, 180€…) que par 9 (930€, 980€…). Étonnant non ?
Instinctivement, on aurait tendance à croire que chaque chiffre de 1 à 9 a la même chance d’apparaître en premier (environ 11,1% chacun). On appelle ça le biais d’équiprobabilité.
Mais en réalité… ce n’est pas du tout le cas !
Comment comprendre cette non-uniformité ?
- Entre 1 et 2, on double la valeur → +100% d’augmentation.
- Entre 9 et 10, on ajoute seulement +11,1%.
Résultat : l’intervalle [1 ; 2] « couvre » plus de nombres significatifs que l’intervalle [9 ; 10].
2. La loi de Benford
La loi de Benford décrit la répartition des premiers chiffres dans de nombreux ensembles de données (ce n’est pas non plus applicable partout, on le verra dans la suite).
En fait, cette loi a été observée dès 1881 par l’astronome américain Simon Newcomb, qui avait remarqué que les premières pages (donc celles qui commençaient par 1, 2…) des tables de logarithmes étaient plus usées que les autres. Mais son article est passé inaperçu.
Ce n’est qu’en 1938 que Frank Benford a redécouvert le phénomène, en analysant des milliers de données réelles (longueurs de fleuves, cours de Bourse, etc.). C’est son nom qui est resté, même si l’idée vient de Newcomb.
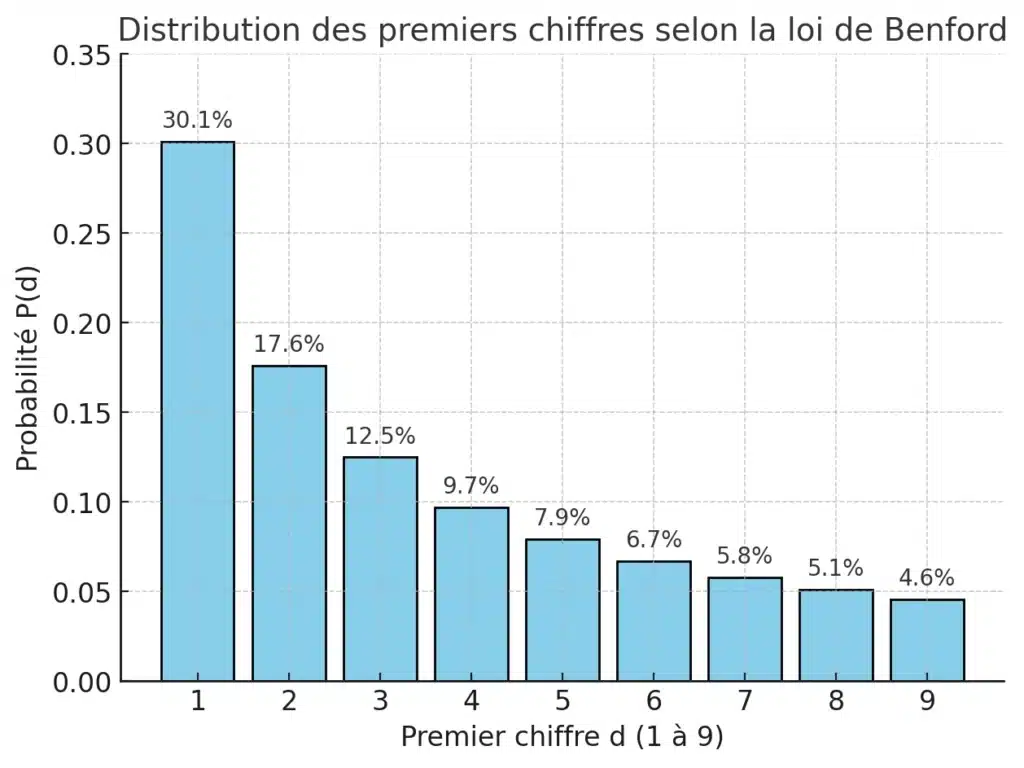
Si l’on note [math] d [/math] le premier chiffre d’un nombre, la loi affirme que la probabilité qu’un nombre commence par [math] d [/math] est donnée par la formule :
P(d) = \log_{10}\Big(1 + \tfrac{1}{d}\Big)où [math] d \in {1,2,\dots,9} [/math].
Concrètement :
- [math] P(1) = \log_{10}(2) \approx 0.301 [/math] → environ 30% des nombres commencent par 1.
- [math] P(9) = \log_{10}(10/9) \approx 0.046 [/math] → à peine 4,6% des nombres commencent par 9.
On retombe donc exactement sur ce que montrait l’histogramme précédent (de façon empirique) : une décroissance nette du chiffre 1 vers le chiffre 9.
Voici une vidéo super intéressante à consulter pour bien comprendre ! Elle peut aussi vous donner une idée concrète de la façon dont vous pourriez présenter pour rendre ça un peu plus vivant.
II. Détecter l’anormal dans les données fiscales
1. Les tests statistiques : comparer théorie et pratique
Imaginons une entreprise X qui déclare 1 000 montants de factures à l’administration fiscale. On extrait les premiers chiffres de ces montants et on les compare à la loi de Benford.
Principe du test du [math]\chi^2[/math] :
On calcule, pour chaque chiffre [math]d[/math], l’écart entre la fréquence observée [math]O_d[/math] et la fréquence théorique [math]E_d[/math] donnée par Benford.
La statistique est :
\chi^2 = \sum_{d=1}^9 \frac{(O_d - E_d)^2}{E_d}- Si [math]\chi^2[/math] est petit → les données suivent bien Benford → pas de raison de suspecter une fraude.
- Si [math]\chi^2[/math] est grand → la répartition est trop différente → alerte possible.
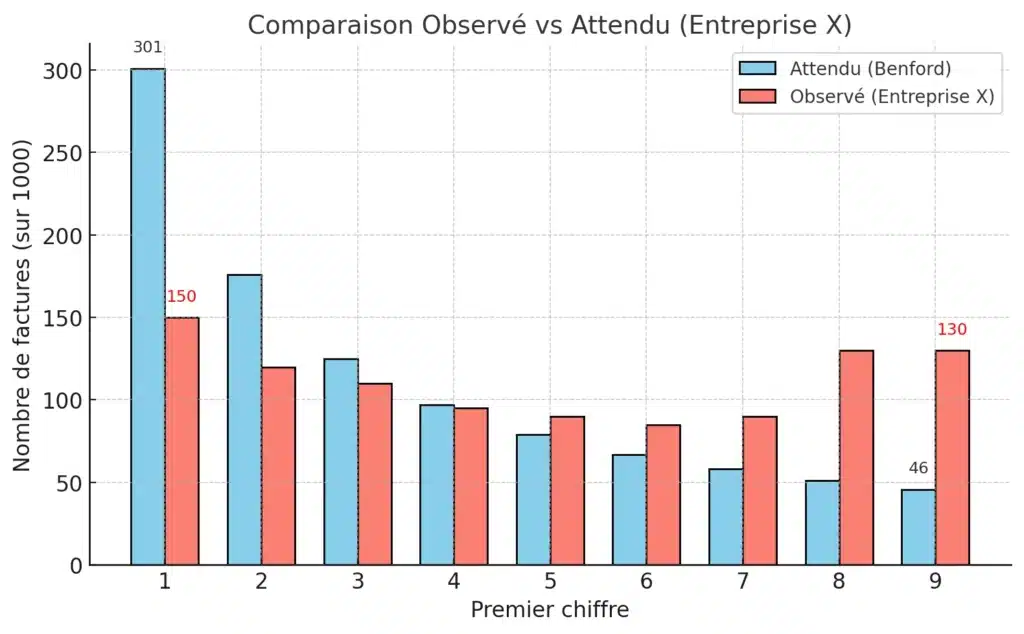
Exemple chiffré (Entreprise X) :
- Fréquences attendues pour 1000 factures : [math]E_1 \approx 301[/math], [math]E_9 \approx 46[/math].
- Observé : seulement 150 factures commençant par 1, mais 130 commençant par 9.
- Calcul : [math]\frac{(150-301)^2}{301} \approx 75.8[/math] et [math]\frac{(130-46)^2}{46} \approx 151.5[/math].
2. Autres lois et distributions
Oui, mais elle n’est pas toujours applicable : par exemple, les salaires d’une entreprise sont souvent bornés et regroupés autour d’une moyenne. Ici, ce n’est pas Benford qui aide, mais la loi normale.
En statistique, quand une variable suit approximativement une courbe en cloche (la loi normale), la plupart des valeurs sont proches de la moyenne [math]\mu[/math]. L’écart par rapport à cette moyenne est mesuré par l’écart-type [math]\sigma[/math].
On définit alors le z-score :
z = \frac{x - \mu}{\sigma}- Si [math]|z| \leq 2[/math] → la donnée est « normale » (95% des cas).
- Si [math]|z| > 3[/math] → la donnée est extrêmement rare, donc suspecte.
Exemple concret de fraude : les notes de frais
Imaginons que dans une entreprise Y, la plupart des employés déclarent des notes de frais de déplacement autour de 200 €, avec une moyenne [math]\mu = 200[/math] et un écart-type [math]\sigma = 40[/math].
- Un employé déclare 210 € → [math]z = (210-200)/40 = 0.25[/math], rien d’anormal.
- Mais un autre déclare 450 € → [math]z = (450-200)/40 = 6.25[/math].
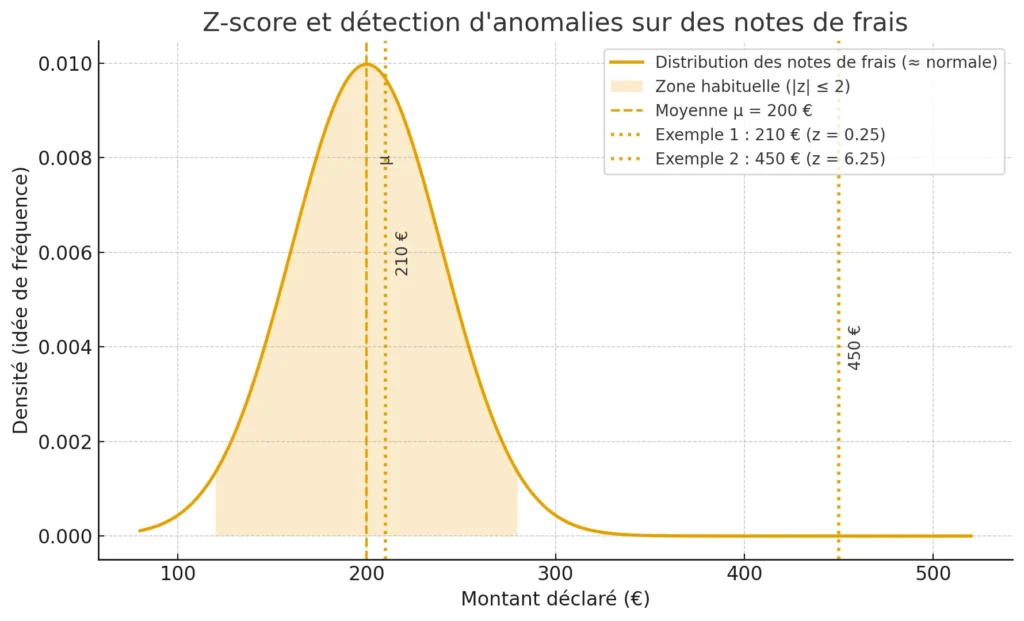
Dans un cas réel, l’administration fiscale pourrait donc identifier cette dépense comme hautement suspecte (typiquement une fraude par gonflement de note de frais).
III. Des maths à la pratique : limites et élargissements
1. Limites de Benford et des tests statistiques
Même si la loi de Benford est puissante, il faut garder en tête qu’elle ne marche pas partout.
Exemples où Benford ne s’applique pas :
- Des prix fixés artificiellement (par exemple, tous les produits d’un magasin entre 10 et 20 €).
- Des salaires plafonnés (beaucoup d’employés payés au SMIC → tous les chiffres commencent pareil).
- Des petits échantillons (trop peu de données → on peut obtenir des écarts aléatoires).
Dans ces cas, si on applique Benford sans réfléchir, on risque de crier à la fraude… alors qu’il n’y en a pas. Ce sont des faux positifs.
2. Vers des outils plus modernes
Aujourd’hui, on va plus loin que Benford et le [math]\chi^2[/math]. Les administrations fiscales et les cabinets d’audit utilisent aussi des méthodes modernes issues de l’intelligence artificielle et du machine learning.
Exemple : on peut construire un modèle qui prend en compte :
- la distribution des premiers chiffres (Benford),
- la répartition des montants (loi normale, z-scores),
- la fréquence des transactions par fournisseur,
- la régularité des dates de factures,
- et même des corrélations inhabituelles (par ex. un employé qui valide toujours les factures les plus grosses).
Avec ces données, on entraîne un algorithme (régression, arbre de décision, réseau de neurones) qui peut classer les entreprises selon leur probabilité de fraude.
Petit exemple
Imaginons un contrôleur qui étudie deux entreprises A et B :
- Les deux ont un chiffre d’affaires similaire.
- Mais l’entreprise A a une répartition des factures qui suit Benford, des salaires cohérents, et des fournisseurs stables.
- L’entreprise B, au contraire, a une anomalie sur les premiers chiffres, des notes de frais très dispersées et un fournisseur qui facture 3 fois plus cher que la moyenne.
Le modèle attribue alors une probabilité de fraude élevée à l’entreprise B, ce qui permet de cibler l’audit là où c’est le plus utile.
Conclusion
La fraude fiscale existe depuis longtemps, mais aujourd’hui les mathématiques donnent aux enquêteurs un avantage décisif. Moralité : toujours respecter les règles !
On espère que ce sujet vous aidera, et que vous saurez l’exploiter au mieux pour briller à votre épreuve !






